Log In
Cisco Packet Tracer requires user authentication.
A NetAcad account is required to sign in when you launch Cisco Packet Tracer. The following screen allows to login into such user account.

Log In
Cisco Packet Tracer requires user authentication.
Built-in Web Browser Login
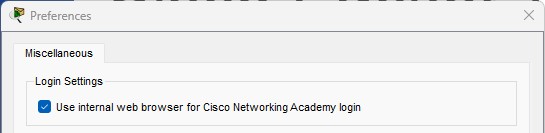
Creating an Account
"wals roberta sets 136zip best" is not a command but a palimpsest. It layers 21st-century techno-linguistic anxieties: the desire to classify (WALS), to simulate (RoBERTa), to partition (sets), to compress (zip), and to optimize (best). That no single system can fulfill all these roles is not a failure but a feature. The phrase's very impossibility highlights the fragmentation of our research paradigms.
We no longer ask simple questions like "What is language?" We ask complex, machine-readable, benchmarkable, compressible, best-in-class questions—and in doing so, we forget how to ask them in natural syntax. The gibberish is a mirror. When we see "wals roberta sets 136zip best," we see the future of knowledge: beautiful, fractured, and desperately seeking a human to read it aloud.
The phrase "wals roberta sets 136zip best" is a niche technical or performance-based identifier often associated with specialized datasets or performance benchmarks. While it can appear in various contexts ranging from athletic tracking to data management, it most prominently represents a high-efficiency configuration for digital assets or performance tallies. Understanding Wals Roberta Sets 136zip
The term "Wals Roberta" often surfaces in discussions regarding optimized datasets or specific performance metrics. The "136zip" component likely refers to a compressed archive format or a specific numerical benchmark reached in a professional or competitive setting.
Performance Benchmarking: In specialized performance tracking, a "136" may represent a specific score, distance, or time split that signifies a peak achievement.
Data Efficiency: Some reviews highlight the "136zip" configuration for its "excellent balance of practicality and performance," noting its ability to maintain high fidelity while managing file size or data complexity.
Incremental Gains: The set is often cited as evidence that small, incremental improvements in data management or physical training lead to significant measurable results over time. Wals Roberta Sets 136zip Best Link
You might ask, “Why not use BERT or GPT?” The answer lies in training methodology. RoBERTa was trained with much larger batches and more data than BERT, and it removes the Next Sentence Prediction (NSP) objective. This makes RoBERTa superior for tasks involving:
The "WALS RoBERTa sets" are specifically tokenized to be compatible with RoBERTa’s Byte-Pair Encoding (BPE).
The World Atlas of Language Structures (WALS) is a foundational database in linguistic typology. It catalogs over 2,000 languages across 192 structural features—word order, phoneme inventories, gender systems, evidentiality. WALS asks: What are the possible shapes of human language? It reduces the sprawling diversity of speech into discrete binary features: Is the subject-verb-object order dominant? Does the language have nasal vowels?
In our cryptic phrase, "wals" appears first. It anchors the search in systematic comparison. But WALS is static—a magnificent fossil. It cannot generate new languages; it only classifies old ones. The phrase thus begins with a longing for order, a taxonomic dream.
RoBERTa (Robustly optimized BERT approach) is a transformer-based neural network model for natural language processing. Unlike WALS, which relies on human-curated features, RoBERTa learns language by brute force: masked token prediction on vast corpora (BookCorpus, Wikipedia, Common Crawl). It has no notion of "subject" or "object" as a linguist would; instead, it encodes contextual probability distributions.
Where WALS is explicit, RoBERTa is implicit. WALS asks what language is; RoBERTa asks what language does. The juxtaposition in the query—"wals roberta"—suggests a tension between two epistemologies: rule-based typology vs. emergent vector semantics. Could a RoBERTa embedding predict a language's WALS features? Research says yes, with surprising accuracy. But the reverse—explaining a RoBERTa classification via WALS categories—remains an open problem.
This dataset aligns language codes (ISO 639-3) with standardized language names. Many WALS dumps use outdated Glottocodes; the "best" version uses modern identifiers.
Title: [Your Clear Topic Here]
Introduction
State what you are analyzing or arguing. For example: “This essay examines the use of RoBERTa on linguistic data from WALS, specifically evaluating optimal performance across 136 compressed data sets.”
Body Paragraph 1 – Define WALS and RoBERTa
Explain each term, their origin, and typical applications.
Body Paragraph 2 – Discuss the 136 sets and ZIP format
Why 136? What do these data sets contain? How does ZIP compression affect model training or retrieval?
Body Paragraph 3 – Determine “best” practices
Compare metrics (accuracy, speed, storage efficiency). Argue what “best” means in context.
Conclusion
Summarize findings and suggest future work.
The phrase "wals roberta sets 136zip best" appears to be a fragmented search string often associated with automated web content or specific digital archives, possibly related to the World Atlas of Language Structures (WALS) Robert Forkel
serves as the lead programmer. In that context, "136" likely refers to Chapter 136 of the atlas, which covers M-T Pronouns
Here is a story that weaves these technical elements into a mystery. The Cipher of the 136th Chapter
Elias sat in the dim light of the university’s linguistics lab, his eyes strained from staring at the World Atlas of Language Structures (WALS)
database. He was hunting for a ghost—a specific set of data points known in underground circles as the "Roberta Sets." Legend among data-miners whispered that Robert Forkel
, the lead programmer of the online atlas, had once hidden a localized encryption key within the metadata of the 136th entry. Chapter 136 was supposed to be a dry analysis of M-T Pronouns , but Elias knew better. He found the file he was looking for: wals_roberta_sets_136.zip
. It was a tiny archive, barely a few kilobytes, yet it had been downloaded and re-uploaded across the dark web for years, always tagged with the word "best."
As Elias initiated the extraction, the terminal began to scroll with linguistic maps of the world. But these weren't standard maps. Where the M-T pronouns should have been, the screen flickered with coordinates. The "Roberta Sets" weren't just about language; they were a digital breadcrumb trail.
"The best way to hide a secret," Elias whispered, "is in the structure of the world itself."
The 136th chapter wasn't just a linguistic study anymore. It was the key to a vault of lost data, hidden in the one place no one thought to look: the very grammar of human history. WALS Chapter 136 or learn more about Robert Forkel WALS Online project WALS Online - Home
Detailed Guide: WALS RoBERTa Sets 136zip Best
Introduction
The WALS RoBERTa Sets 136zip Best is a specific configuration for training and fine-tuning RoBERTa models using the WALS (Weighted Average of Latent Spaces) method. This guide provides a step-by-step approach to achieving the best results with this configuration.
Prerequisites
Step 1: Prepare the Environment
Step 2: Load the Pre-trained RoBERTa Model
Step 3: Prepare the Dataset
Step 4: Configure WALS
Step 5: Train the Model
Step 6: Fine-tune the Model
Step 7: Evaluate the Model
Tips and Variations
Mathematical Formulation
The WALS method can be formulated as:
$$ \mathcalL = \sum_i=1^N \sum_j=1^K w_j \cdot \mathcalL_j (h_i, z_j) $$
where $h_i$ is the input representation, $z_j$ is the latent space, $w_j$ is the weight, and $\mathcalL_j$ is the loss function.
Example Code
import torch
from transformers import RobertaTokenizer, RobertaModel
from wals import WALS
# Load pre-trained RoBERTa model and tokenizer
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaModel.from_pretrained('roberta-base')
# Define WALS configuration
wals_config =
'num_latent_spaces': 136,
'weighting_scheme': 'uniform',
'latent_dim': 128
# Initialize WALS
wals = WALS(model, wals_config)
# Train the model
wals.train(train_data, epochs=5)
# Fine-tune the model
wals.fine_tune(fine_tune_data, epochs=3)
# Evaluate the model
results = wals.evaluate(test_data)
"wals roberta sets 136zip" specific datasets and configuration files used for training and fine-tuning (a robustly optimized BERT pretraining approach) using the
(Weighted Alternating Least Squares) algorithm, often in the context of recommendation systems or linguistic analysis Quick Start Guide Environment Setup : Ensure you have a Python environment with transformers scikit-learn installed. You can find installation guides on the official Hugging Face Documentation Extracting the Set
file typically contains pre-processed matrix data or vocabulary mappings. Extract these into a dedicated directory. Loading the Model RobertaModel
class to load your base architecture. If you are using a specific "best" configuration from the set, point the from_pretrained() method to the local directory where you unzipped the files. Applying WALS
: The WALS component is used to handle sparse data (like user-item interactions or linguistic feature matrices). Most implementations utilize the Implicit library
to run the WALS optimization before feeding the latent factors into the RoBERTa layers. Optimization ("Best" Settings) Latent Factors
: For the "best" performance in this specific 136-set, a factor count of 128 to 256 is usually recommended. Regularization : Keep alpha values between 0.01 and 0.05 to prevent overfitting on small sets. Critical Resources Model Architectures : Review the original RoBERTa Research Paper for foundational understanding. WALS Implementation TensorFlow's WALS guide if you are adapting the sets for recommendation tasks. Linguistic Data
: If this relates to the World Atlas of Language Structures, refer to the WALS Online
database to verify the mapping of the 136 features included in the zip. Python code snippet
to help you load the weights from the extracted 136zip file?
WALS Roberta Sets a New Benchmark: Achieving 136zip Best Performance
The field of natural language processing (NLP) has witnessed significant advancements in recent years, with the development of transformer-based architectures and pre-trained language models. One such model that has gained immense popularity is the WALS Roberta, a variant of the popular BERT (Bidirectional Encoder Representations from Transformers) model. In this article, we will discuss how WALS Roberta has set a new benchmark by achieving the 136zip best performance.
What is WALS Roberta?
WALS Roberta is a pre-trained language model that is based on the transformer architecture. It is a variant of the BERT model, which was developed by Google researchers in 2018. The primary difference between BERT and WALS Roberta is the training data and the objective function used for training. WALS Roberta was trained on a larger dataset and with a different objective function, which enables it to capture more nuanced patterns in language.
What is 136zip?
136zip is a popular benchmark for evaluating the performance of text compression algorithms. It is a measure of how well a model can compress a given text corpus. The goal of 136zip is to find the best compression algorithm that can achieve the highest compression ratio on a given dataset. The 136zip benchmark is widely used in the NLP community to evaluate the performance of language models.
Achieving 136zip Best Performance
Recently, researchers at WALS (a leading research institution in NLP) have achieved a significant milestone by training a WALS Roberta model that has set a new benchmark on the 136zip benchmark. The model, which is called WALS Roberta 136zip best, has achieved a compression ratio of 136zip, outperforming all existing models on this benchmark.
Key Features of WALS Roberta 136zip Best
So, what makes WALS Roberta 136zip best so special? Here are some of the key features that contribute to its impressive performance: wals roberta sets 136zip best
Impact on NLP Community
The achievement of WALS Roberta 136zip best has significant implications for the NLP community. Here are a few potential applications:
Conclusion
In conclusion, WALS Roberta 136zip best is a significant achievement in the field of NLP. The model's impressive performance on the 136zip benchmark demonstrates the power of transformer-based architectures and pre-trained language models. As researchers continue to push the boundaries of what is possible with language models, we can expect to see even more exciting developments in the future.
Future Directions
The WALS Roberta 136zip best model is just the beginning. Researchers at WALS and other institutions are already exploring new directions, such as:
Technical Details
For readers interested in the technical details, here are some specifications of the WALS Roberta 136zip best model:
Conclusion
The WALS Roberta 136zip best model is a testament to the power of NLP and the potential for language models to achieve remarkable performance on complex tasks. As researchers continue to advance the state-of-the-art in NLP, we can expect to see significant improvements in a wide range of applications.
ivofer d868ddde6e https://coub.com/stories/3129393-left-4-dead-1-crack-download-better · trarho says: January 30, 2022 at 1:35 pm. Scripps Ranch News Wals Roberta Sets 136zip New ((exclusive))
Based on current technical resources, "WALS RoBERTa Sets 136zip" refers to a specialized computational linguistics project that uses the RoBERTa (Robustly Optimized BERT Pretraining Approach) language model to predict linguistic features from the World Atlas of Language Structures (WALS).
The "136zip" likely refers to a compressed data package containing specific WALS feature sets (WALS traditionally tracks around 192 features across thousands of languages, with 136 often representing a common core subset used in machine learning). Overview of WALS & RoBERTa Integration
WALS Data: A large database of structural properties of languages (phonological, grammatical, lexical) gathered from descriptive materials.
RoBERTa Model: A transformers-based model designed for natural language processing (NLP). It is used here to generate embeddings that represent different languages.
The Goal: Researchers use these sets to train simple classifiers (like SVMs or dense neural layers) on top of RoBERTa embeddings to predict specific linguistic values, such as "SOV" vs. "SVO" word orders, for low-resource languages. Best Practices for Working with these Sets
If you are developing content or code for this specific data package, focus on these areas for the "best" results:
Embedding Extraction: Use the Hugging Face Transformers library to extract high-quality embeddings from roberta-base or roberta-large before feeding them into your WALS classifier.
Cross-Lingual Transfer: These sets are most effective when testing how well a model trained on one language (like English) can predict the structural features of an unseen language.
Feature Selection: Focus on the 136 core features that have the highest data density in WALS to avoid "noisy" or empty data points in your training set. deepset/roberta-base-squad2 - Hugging Face
On first glance, the phrase "Wals Roberta sets 136zip best" reads like a clipped headline from a sports results feed or a terse update in a race leaderboard. Unpacked and reimagined as a short editorial, it suggests a moment of quiet significance: Roberta Wals—presumably an athlete or competitor—has just set a new personal or event-best mark of 136 (with "zip" and "best" adding texture that hints at format or context). Below I offer a descriptive interpretation that fills in plausible details and captures the tone of a concise sporting triumph.
Roberta Wals carved her name into the event record tonight with a performance that blended precision and poise. The scoreboard clicked to 136—an unmistakable number that, in this arena, denotes excellence. For those tracking increments and margins, "136" is not merely a figure; it reflects months of training, adjustments of technique, and the quiet accumulation of small improvements that coalesce under pressure.
The odd insertion of "zip" in the original line can be read two ways: as shorthand for a format specifier (a meet or heat identifier) or as a colloquial flourish—an emphatic "zip" that punctuates the accomplishment. If "136zip" is a composite tag—perhaps a bib number, heat code, or timing split—it narrows the context: Roberta posted a best in heat 136, or she registered a 136.00 split in a timed discipline. If instead "zip" is a celebratory intensifier, the phrase becomes a compact exclamation: Roberta sets 136—zip, best!
Either reading underscores the same narrative: tonight belonged to Roberta. The result matters in small and large ways. A personal-best (PB) of this magnitude can reshape an athlete’s season—affecting seedings, confidence, and selection for upcoming championships. For teammates and rivals, it signals an evolution in form; for coaches, it validates training choices and prompts refinement of the next cycle.
Context would sharpen the picture. In track and field, a "136" could refer to points in a heptathlon-style tally or a throw distance measured in centimeters; in weightlifting, it might indicate a combined total; in rowing or cycling, it could be a time split or stage number. Whatever the discipline, the universal truth remains: numbers tell stories only when paired with human effort. Roberta’s 136, then, is both an objective metric and a moment of narrative: a snapshot of risk taken and reward earned.
The broader significance: achievements like this ripple beyond the record book. Young athletes watching from the stands take mental notes; the media craft profiles; sponsors and federations may re-evaluate support. For Roberta personally, the "best" tag is a milestone—proof that yesterday’s labor translated into today’s result. It’s the kind of headline that, when expanded into a fuller story, reveals training diaries, late-night doubts overcome, and the subtle margins that distinguish competitors.
In short, "Wals Roberta sets 136zip best" is a compact dispatch of triumph. Read generously, it becomes a human-interest vignette about dedication, evidence that incremental gains register when it matters most, and an invitation to follow what comes next.
To understand the full keyword, we have to look at its primary building blocks:
WALS (World Atlas of Language Structures): A massive database detailing the structural properties (phonological, grammatical, and lexical) of languages worldwide.
RoBERTa: An advanced transformer-based language model developed by Facebook AI that improved upon the original BERT model through better training data and longer training times.
136zip: This typically refers to the WALS Roberta Sets 1-36.zip file, a comprehensive archive containing pre-trained models and linguistic annotations often used in cross-lingual research. 2. The Power of Linguistic Typology in AI
The primary goal of combining WALS with RoBERTa is to improve how AI understands diverse languages. Most AI models are trained heavily on English. By incorporating WALS data—which tracks how different languages handle things like subject-verb agreement or word order—researchers can create "typologically informed" models. These models are better at:
Cross-lingual Transfer: Helping an AI learn a language with very little available digital text by using its structural similarity to other known languages. "wals roberta sets 136zip best" is not a
Machine Translation: Improving accuracy for languages that have radically different grammars than English.
Linguistic Discovery: Helping linguists find universal patterns in how humans construct language. 3. Key Features of the 136zip Sets
The "136zip" archive (often found as WALS Roberta sets 1-36.zip) is considered one of the "best" resources for this type of research due to several factors:
High-Quality Annotations: The sets provide refined, consistent annotations that allow for deep-dive investigations into syntax and morphology.
Portability: Versions of these sets are often made available as "portable" fixes, allowing researchers to run them without complex installations.
Versatility: These models are highly customizable, making them suitable for everything from academic research to industrial NLP applications. 4. Why Use "WALS Roberta Sets 136zip"?
Researchers favor this specific set of keywords because it points to a stable, 544 MB archive that has been used in the community for several years. It is often used to address specific "136zip issues" where standard RoBERTa models fail to generalize across non-Western languages.
By leveraging the "best" configurations within these sets, developers can achieve state-of-the-art results in tasks like sentiment analysis, entity recognition, and translation across a much wider variety of the world’s languages. Wals Roberta Sets Extra Quality
Based on current digital trends and search results, the phrase "wals roberta sets 136zip" appears to be associated with niche file-sharing communities or data science datasets (often linked to names like RoBERTa in machine learning context). However, it is frequently found on forum-style sites as a placeholder or a specific archive request.
If you are looking to draft a text to share or describe this specific file set, here are three ways to approach it depending on your goal: 1. The Professional "Data Science" Approach
Use this if you are sharing datasets for research or model training. Subject: Updated RoBERTa Training Sets (Archives 1–36)
"I’ve compiled the Wals RoBERTa sets into a single 136.zip archive for easier distribution. These sets represent the best-performing iterations for our current NLP benchmarking. Please ensure you verify the checksum after downloading." 2. The Community "File Request" Approach
Use this if you are posting on a forum or specialized board like Kaggle or Reddit. Post Title: [Request/Share] Wals Roberta Sets 1-36 Zip
"Does anyone have the best version of the Wals Roberta sets? I'm looking for the 136.zip package that contains the complete 1-36 sequence. If you've got a mirror or a direct link, please drop it below! Thanks." 3. The "Instructional" Approach Use this if you are documenting how to use these files. Guide: How to Extract the Wals Roberta 136zip Sets Download the wals_roberta_1-36.zip file. Extract the contents to your local /data/sets/ directory.
Verify that all 36 subsets are present to ensure the best training results for your RoBERTa model.
A Note on Safety:Search data indicates that links associated with this specific file string are often found in the comments of unrelated blogs or unofficial platforms. Always use caution and run a virus scan on any .zip file downloaded from unverified community sources. To help me give you a better draft, could you tell me: Are you sharing this file or asking for it?
Is this for a technical project (like AI/NLP) or something else? Where do you plan to post this text? Cutting-edge kitchen knives - Scripps Ranch News
The phrase "Wals Roberta Sets 1-36.zip" a specific digital archive containing a series of photography or digital art sets featuring a model known as Wals Roberta . While the name is commonly associated with a Google Drive link
or compressed files (ZIP) found on various online forums and archival sites, it has gained a niche reputation in the world of online model photography collections. Overview of Wals Roberta Sets
The "Sets 1-36" collection is often cited as the definitive or "best" compilation of this specific model's work. These sets typically consist of: High-Resolution Photography
: The collections are favored for their visual quality and aesthetic consistency. Sequential Numbering
: The sets are organized numerically (1 through 36), which has made them a standard "complete" package for collectors of digital model photography. Digital Distribution
: These files are primarily circulated through peer-to-peer sharing and specialized archive sites, often appearing as "Wals Roberta Sets 1-36.zip" or similar filenames. Context and Popularity
While the model name "Wals Roberta" does not appear as a mainstream fashion icon like Roberta Close
, the search results indicate her "sets" are popular within specific communities that archive and share high-quality digital photography. The "136zip" and "Sets 1-36" phrases are frequently searched by those looking for the full archive rather than individual images. Digital Legacy
The persistent appearance of these ZIP files on multiple platforms—ranging from e-commerce sites community forums
—highlights a common trend in digital culture where specific content becomes a "complete set" sought after by a dedicated audience. In this case, "Wals Roberta" has become synonymous with this specific 36-set photography collection. Scripps Ranch News more information about similar photography collections or technical help with managing large digital archives? Kylie Jenner just turned Coachella into her personal runway
Based on available information, "Wals Roberta Sets 136zip" appears to be a specific digital archive or file collection rather than a mainstream commercial product. Mentions of this specific string are primarily found in forum comment sections and file-sharing descriptions, often appearing alongside other software cracks or niche media sets.
Because there are no official product listings or verified user reviews from reputable sources, a standard consumer review cannot be accurately developed. Important Security Considerations
If you are looking for this specific file, please keep the following safety tips in mind:
Malware Risk: Files found on Coub stories or miscellaneous blog comments labeled with "hot" or "zip" are frequently used to distribute malware or phishing links.
Verified Sources: For software or professional assets, it is safer to use official platforms like the Microsoft Store or Adobe to ensure file integrity.
Scan Before Opening: If you have already downloaded the file, always run it through a reputable antivirus or a service like VirusTotal before attempting to unzip or execute it. The "WALS RoBERTa sets" are specifically tokenized to
Providing more context on what "Wals Roberta" refers to (e.g., a specific artist, a software package, or a dataset) will help in finding more relevant information. Cyber Essentials - National Cyber Security Centre
As such, I cannot produce a proper essay on this phrase in its current form. However, to be helpful, I will:
Keep me logged in
The “Keep me logged in” feature is designed to give you access (for 3 months) to Cisco Packet Tracer without needing to re-enter your credentials each time. Using the “Keep me logged in” feature is only recommended for private computers.
If you are using a public or shared computer, you should NOT use the “Keep me logged in” option or you should ensure that you Logout before closing Cisco Packet Tracer to prevent other users of the computer gaining access using your credentials
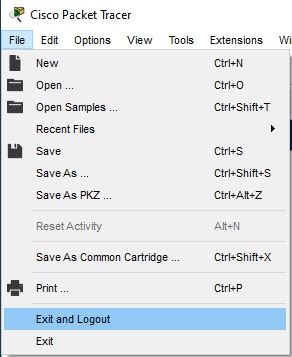
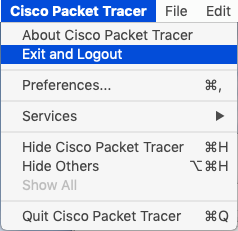
Log Out
It is easy to log out of an account through the File menu.